
Hololink - Internet as a knowledge-base 及 Information overload
Oct 29, 2020
定義
根據維基百科的定義 Knowledge base 的概念一開始主要是指稱電腦用以儲存複雜的「結構性資料」或「非結構性資料」的方式,隨後被 database 一詞概括。後來套用在個人身上,以Personal knowledge base指稱人處理「結構性資料」或「非結構性資料」的方式。與電腦系統的 knowledge-base 不同,Personal knowledge base 存有建立者的主觀資訊,其定義更富有彈性。只要以系統化建構而成的系統都可以稱為 Personal knowledge base,例如筆記本、你現在閱讀的 Notion 頁面等等。而把 knowledge-base 可視化後即成為 knowledge graph。
Internet as a knowledge-base 及其困難
隨網際網路盛行,單元與單元間的連結速度提升,由於資料產出的速度過於快速與龐大,個人、企業、群體電腦系統的記憶體沒有辦法以單一的 database 儲存下這些資訊,因此轉由 Internet 作為獨立的載體,藉由超連結、文件、多媒體組成一複雜的群落,人們取得並儲存資訊的習慣改變,從過往記憶資訊本體的形式轉由現今記憶「載體在何處」的形式,Internet as a knowledge-base 的概念逐漸浮現。。
人們記憶的主體從節點,逐漸演化成記憶「連結」。例如說,人們記憶單一事件不是他的詳細脈絡,而是自己可以在「什麼地方」找到詳述這些脈絡的文件。人們不再細細琢磨自己如何記憶龐大的資料,而開始思考,既然我們將這樣的任務交付給電腦,我們剩餘下來的記憶空間應該要換成儲存什麼?
我認為這樣的思考脈絡並不普存於每個個體,他不是一個既定的因果關係,「發覺自己有剩餘的記憶空間」進而思考「我該怎麼活用這樣的空間」這件事並不是每個人都會遇到的問題。卻是一個系統優化自身效率時肯定會遭遇的難題。
現存的網際網路,逐漸成為我們每個人的 knowledge-base,每個人記憶的節點從文章本身的內容,演化為以「關鍵字」構成的連結。我們傳遞知識的方式也有了劇烈的改變,為了應付巨量的資訊,比起過往,更多協助個人理解複雜資訊的個體出現,他們將知識的分野切得更細緻、更微觀。這樣的角色原先由具有社經地位的人所壟斷,現在則是每個人都有所機會。
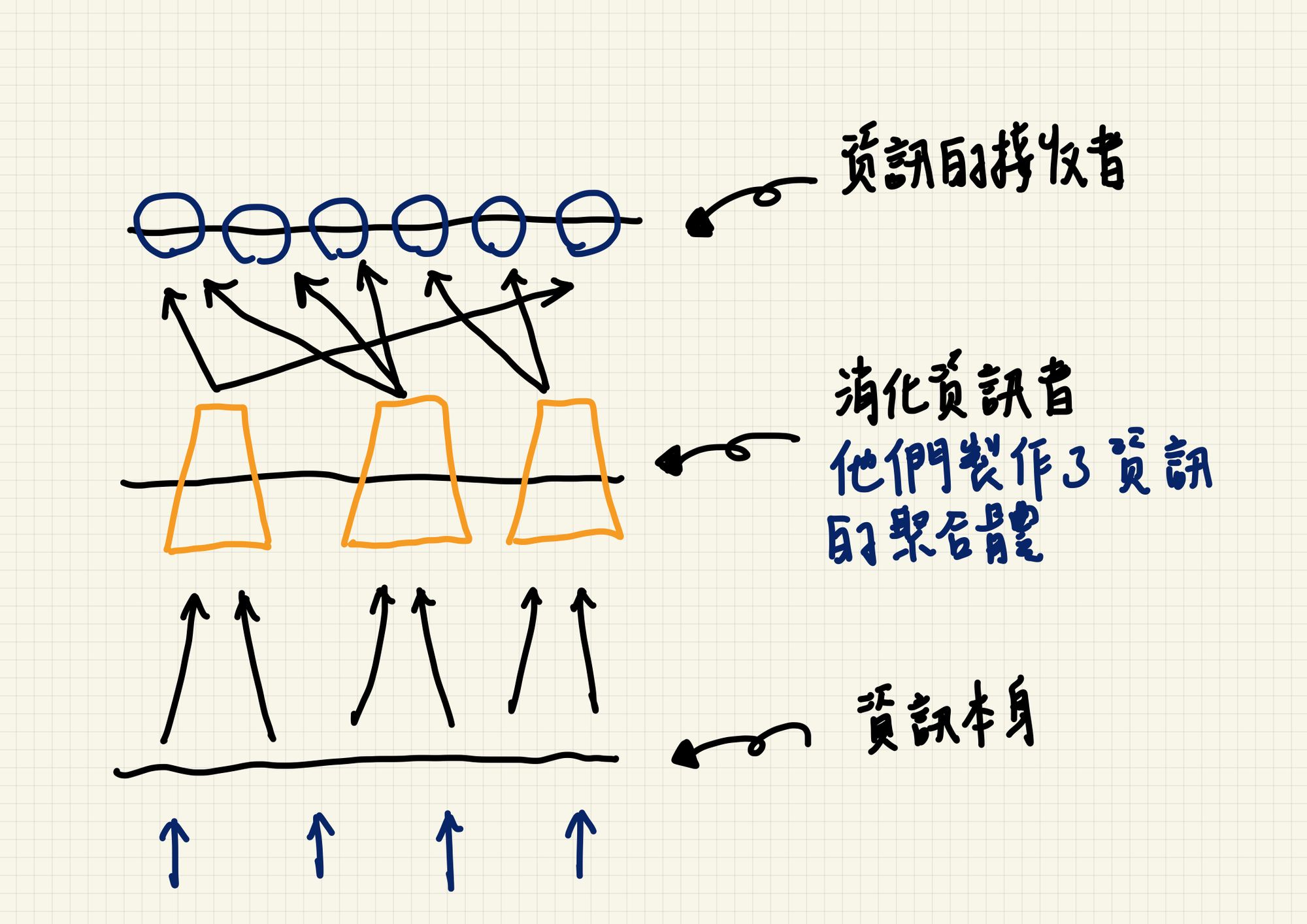
我們可以在這裡將資訊分成三個階層來看待,第一個階層是資訊本身,第二個階層是消化這些資訊並產生資訊聚合物的個體,第三個階層則是吸收這些資訊的個體。我們這個世代的資訊複雜化不僅是資訊本身,第一個階層的總量以指數提升,而第二個階層更進行著劇烈的演化,他們的數量不斷增加,網站的架設更加方便,諸如 Wordpress 和 wix 等服務供應商蜂擁出現,而系統也不斷在思考如何提供這些人更多的資源。如 patreon、Linkcoin、Matter、Medium、以及任何使用 paywall 的文字載體,都在強化這件事。
*第二階層與第一階層不一定是分開的,他們有可能是同一個角色,然而這邊為了論述的方便性,將兩者拆分為二,只單獨看待他們最單純的元素,第一層:創造者;第二層:聚合者。
Internet as a knowledge-base 這個概念因為總數的提升而越來越複雜,同時整個系統的效益也不斷增加。然而對個人而言問題就在這個時刻出現了:資訊過載。
資訊過載
最近在看 Twitter 時看到一篇文章非常有趣,是由 Roam research 的創辦人 Conor White-Sullivan 寫出來的。
::twitter{url=https://twitter.com/Conaw/status/1319062548260421638}
當然這只是一切狀況的冰山一角,但由於這個功能實在太有趣,導致我想要特別將它提出來。
資訊過載並不是現在才有的問題,它一直都是進行式,每個時代都有自己資訊過載的特性以及他們對抗它的方法,例如妖魔化印刷術、妖魔化電視等等都是一些極端的反抗方式。
**資訊超載的特點在於,它普遍發生於人們無法分清楚資訊的公領域與私領域的交界之時。**例如說,在滑臉書時,個人由該篇資訊的客觀數據:按讚數、分享數理解到這邊文章或許在特定狀態具有代表性,人們藉由這樣的客觀資料判斷這個資訊自己應該知道。然而他卻很難正確判斷這件事到底與自己有什麼關係?舉臉書而言,臉書並不會讓你知道這篇文章準確說來為什麼會出現在你的塗鴉牆上。也就是說這個資訊處於公領域,它是一個公開的事實,但是人們無法判斷這是雜訊還是有意義的資訊,人們難以判斷這個資訊是否應該收入個人的私領域,臉書沒有提供任何根植於這個個人總結出的指標,至少當前沒有。(什麼是基於個人,協助判斷是否要讓資訊進入私領域的指標呢?)1
人們若沒有深入自己的知識體系,並且經由訓練理解哪些資訊對自己有益,他們會持續處在這種公私領域難分的狀況,被與自己無關,無法彙整進知識體系內的雜訊淹沒。這樣的判斷能力需要訓練,它要求個人付出大量的時間,以當前的例子而論就如同聚合者與創造者,要能夠不斷爬梳自己內部的世界,諸如小說家以自我內在書寫出的故事;聚合者快速吸收資訊,如科技島讀,張羅與這些資訊有關的知識,書寫成文章。
除此之外還有眾多辦法,但多建立在逃避或是拒絕之上,並沒有真正面對**「資訊爆炸」的核心問題:如何協助個人判斷哪些資訊進入私領域是有益的?**
Hololink
Hololink 最重要的終極目標就是:「協助人們建構個人知識圖譜,並且可視化它。」
同時我們將從這一個基本任務中延伸出各式各樣的應用,來幫助人們消化資訊、連結知識。然而實際上該怎麼做呢,必須從這一張圖開始說起。
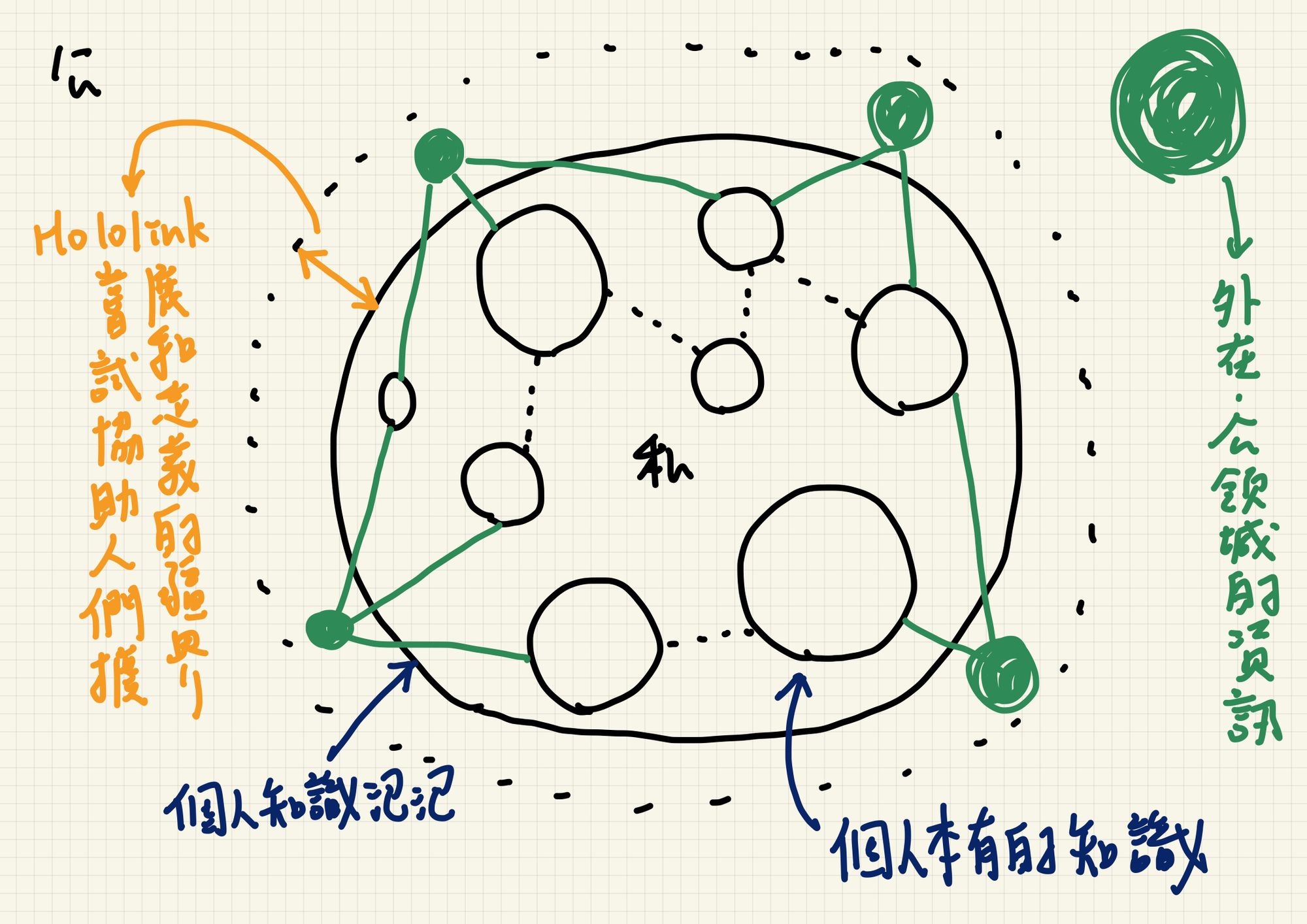
首先要來定義資訊與知識:知識是與自身體系鏈結的資訊。也就是說,我們平常在網路上接觸到的事物,諸如他者言論、新聞、任何論述,在與自身體系產生連結之前,都只是單純的資訊。這些資訊若只是穿過我們的身體,沒有被任何泡泡包裹住,它就是雜訊。如果它被某些泡泡包裹住,納入自身體系之內,卻沒有與本有的知識進行連結,它也是雜訊。
舉例來說,任何一個閱讀這篇文章的人,都有一個閱讀上的前提:想理解 Hololink 想完成什麼事,這是一個意念上的泡泡。於是你將這篇文章提到的概念與資訊包進了這個泡泡裡面,接著若期待這些資訊不成為雜訊,它主動要求你找到與這些資訊對應的內在知識。例如將資訊過載這個概念連結到哈拉瑞《人類大命運》中的最後一章:信數據得永生,並推敲兩者之間的差異,或思考到底該怎麼突破這件事。那恭喜你,這篇文章對你來說不再是雜訊,它對你有充分的意義。
轉換成上述公私領域的語法則是,這篇文章不再是懸浮在公領域中的無意義之物,而是被你納入私領域,並且清楚其中界限與連結的知識。
Hololink 想協助人們建立這個泡泡,樹立嶄新的內在指標讓個人有判斷依據,並有效擴展知識的疆界。
難題:抽象且複雜的世界
然而為了執行這件事有非常多的難題:
- 我該如何辨識個人本有的知識?
- 我該如何辨識個人本有知識之間的連結?
- 我該如何辨識出個人的知識泡泡
- 我該如何辨識出外在、公領域資訊與私領域知識之間的連結?
你可以發現這些難題最基本的元素就是:我該如何細分資訊,並進而細分知識,讓它可以被輕易地辨認出來,這要做到什麼程度呢?做到我用簡單的 if condition 加上一個 list 就可以完成 if 'a' in ['a','b','c','d','e']: 這樣我才能在有限的運算資源中,讓廣大的知識同時聚集在同一個面上。換句話說,我不可能將數十篇數千字的文章同時貼在使用者的牆上,以條列式羅列出來,然後說這是你的知識圖譜,並且完成上述那些目標,這樣對個人是毫無作用的。
例如著名的人因科技閱讀清單(這還只是其中的十分之一):
- Adams, Catherine. n.d. Researching a Posthuman World — Interviews with | Catherine Adams | Palgrave Macmillan. http://www.palgrave.com/us/book/9781137571618.
- “AI Principles.” n.d. Future of Life Institute. https://futureoflife.org/ai-principles/.
- !!! Andreotti, Vanessa. n.d. “Soft versus Critical Global Citizenship Education | Development Education Review.” https://www.developmenteducationreview.com/issue/issue-3/soft-versus-critical-global-citizenship-education.
- Aniyia, Jennifer, Mara, Astrid &. 2017. “Zebras Fix What Unicorns Break.” Jennifer, Mara, Astrid & Aniyia (blog). March 8, 2017. https://medium.com/@sexandstartups/zebrasfix-c467e55f9d96.
- !!! Bosker, Bianca. 2017. “Addicted to Your IPhone? You’re Not Alone — The Atlantic.” November 2017. https://www.theatlantic.com/magazine/archive/2016/11/the-binge-breaker/501122/.
- Bret, Victor. n.d. “A Note about ‘The Humane Representation of Thought.’” http://worrydream.com/TheHumaneRepresentationOfThought/note.html.
- Bret, Victor. n.d. “Bret Victors ‘Inventing on Principle’ — and a Few Things It Inspired — Mozilla Hacks — the Web Developer Blog.” Mozilla Hacks — the Web Developer Blog. https://hacks.mozilla.org/2012/04/bret-victors-inventing-on-principle-and-a-few-things-it-inspired.
- Bret, Victor. n.d. “Explorable Explanations.” http://worrydream.com/ExplorableExplanations/.
這類閱讀清單,是從紙本時代遺留到現今的幽靈,那時人們取用資訊的方法頂多以三個欄位就可以交代完畢:(內容名)(作者)(索書碼)。這樣的方法對提供者而言快速且方便,它甚至可以用來表彰自己的學識淵博。然而對於任何一位接收者而言它都是非常沉重的負擔。進入了網路時代後,我們將索書碼改為超連結,但其本質依然沒有變化,人們依然使用著這種數十年前的結構做為自身的知識圖譜。
藉由這樣的結構來思考上述那些目標的可行性,我們發現事情變得清楚得多。我們要做的第一件事是深入它的下層階層,也就是這些文章,分析它的組成單位:文字,並把分析完成的結果化為閱讀清單的其餘欄位:
(內容名)(作者)(URL)|(分析的結果:載體、對外連結、關鍵字、字數…)
到這裡為止我們做的事情會跟書目管理工具,諸如 Endnote 或是 Evernote 相近。然而接下來我們要做的就截然不同了,請接著閱讀:Hololink 的方法論 。
Footnotes
-
利用這件事情來增加廣告點閱率在各大聚合者的平台逐漸出現,諸如「與你訂閱相同內容的人也喜歡這個。」但是數量仍然稀少。我們可以從兩個層面來看待這件事,第一是聚合者發覺人們開始注意演算法的力量與施力的方向,第二個則是聚合者們意識到如此一來內容與內容的轉換率更高,單一廣告的觸及可以更有效率,我個人悲觀地認為其中的原因後者占大多數。我們認為這一件事情會被更廣泛的大眾所認知:我們必須擁有一種演算法,它幫助到我們的同時必須告訴我們為什麼它會得出這種結果。且該軟體的介面必須擔負起解釋清楚的責任。我將這種責任稱為 Explainable Algorithm,他必須被妥當得解釋,如此一來人們才會知道為什麼要在這種演算法的幫助下做決定,並且該怎麼做才好。Hololink 的推薦系統將完全在這種邏輯下運作,之後會有更深度的解釋。 ↩